Predict
“All models are wrong, but some are useful.”
— George E.P. Box
Apr 3, 2024
Overview
- Orientation
- Predictive modeling
- Workflow with
tidymodels
- Workflow with
Process
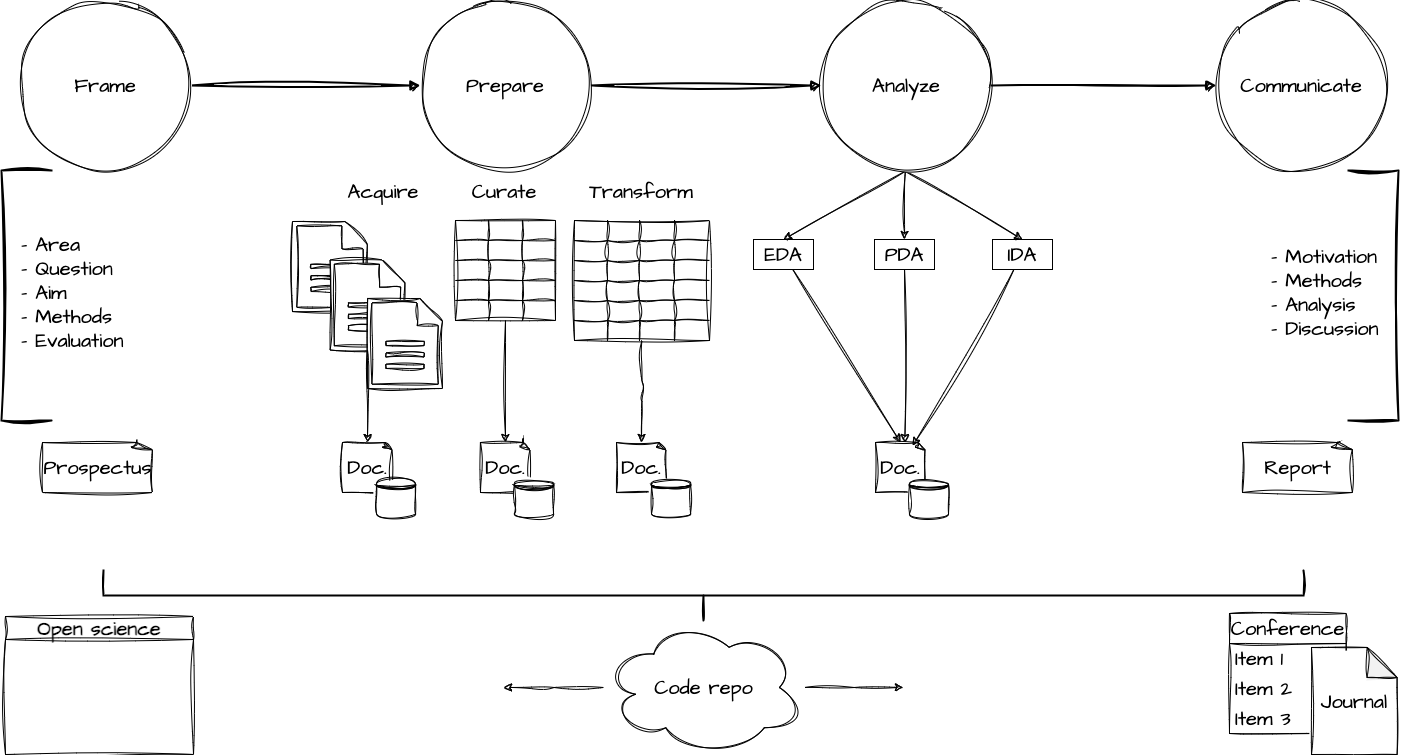

Orientation
Predictive Data Analysis
Goals
- Prescribe actions
- Examine outcome-predictor relationship
- Assess hypotheses
When to use
- To perform tasks
- Specific knowledge gap
- Alternative to inference
How to use
- Identify, Inspect, Interrogate, Interpret
- Iterative:
- Features, Model
Predictive modeling
Classification vs. Regression tasks
- Classification: Predicting a categorical variable
- Regression: Predicting a continuous variable
Features: tokenization
In text analysis, features are often linguistic units (tokens).
Features: metadata
But they can also be other types of variables such as metadata.
Features: text features
Or derived features.
Workflow with tidymodels
A. Identify
- Variables
- Splits
- Recipe
B. Inspect
- Features
C. Interrogate
- Model
- Tune
- Fit
- Evaluate
D. Interpret
- Predict
- Evaluate
- Explore
Identify: variables
- Outcome variable: The variable you want to predict
- Predictor variables: The variables you will use to make the prediction
| Variable | Type | Description |
|---|---|---|
gender |
Outcome | Aim to predict ‘female’ or ‘male’ |
text |
Predictor | Text data to predict gender |
Identify: Splits
- Training set: Used to train, tune, and evaluate the model
- Testing set: Used to evaluate the final model
Identify: Recipe
- Recipe: A blueprint for how to process the data
Identify: Recipe
- Feature selection: Choosing the most relevant variables
Identify: Recipe
- Feature engineering: Deriving new variables and transforming existing ones
Interrogate: Model selection
- Model specification: A blueprint for the model
- Model family: The type of model to use (e.g., logistic regression, random forest)
- Engine: The software that will fit the model (e.g.,
LiblineaR,ranger) - Hyperparameters: Settings that control the model’s behavior (e.g., number of trees in a random forest)
| Model | Family | Engine |
|---|---|---|
logistic_reg() |
Logistic regression | LiblineaR |
decision_tree() |
Decision tree | C5.0 |
random_forest() |
Random forest | ranger |
svm_linear() |
Support vector machine | LiblineaR |
Each model has hyperparameters that can be tuned to improve performance.
Interrogate: Model selection
- Model specification: A blueprint for the model
The logistic_reg() model has a penalty hyperparameter that controls the minimum number of observations in a node. Tuning this parameter and the max_tokens() filter will help the model generalize better.
Interrogate: Model selection
Create a workflow that combines the recipe and model specification.
Interrogate: Model tuning
- Hyperparameter tuning: Finding the best settings for the model
- Resampling: Using the training set to estimate how well the model will perform on new (slices of) data
Interrogate: Model tuning
Choose the best hyperparameters and finalize the workflow.
Interrogate: Fit the model
- Fit the model: Train the model on the training set
- Cross-validation: Repeatedly train and evaluate the model on different slices of the training set
Interrogate: Evaluate the model
Performance metrics: Measures of how well the model is doing
Classification
- Confusion matrix: A table showing the model’s predictions versus the actual outcomes
- ROC curve: A graph showing the trade-off between true positive rate and false positive rate
Regression
- RMSE: Root mean squared error
- Standard deviation of residuals: How much the model’s predictions deviate from the actual outcomes
Identify: Recipe (x2)
Our previous feature selection:
- Tokenization: words
- Feature engineering: tf-idf
- Feature selection: 150 tokens
Interrogate: Model selection (x2)
Update the workflow with the new recipe.
Interrogate: Model tuning (x2)
Update the grid and resampling.
Interrogate: Fit the model (x2)
- Fit the model: Train the model on the training set
- Cross-validation: Repeatedly train and evaluate the model on different slices of the training set
Interrogate: Evaluate the model (x2)
Performance metrics: Measures of how well the model is doing
Identify: Recipe (x3)
Our previous feature selection:
- Tokenization: words
- Feature engineering: tf-idf
- Feature selection: 150 tokens
Interrogate: Model selection (x3)
Update the workflow with the new recipe.
Interrogate: Model tuning (x3)
Update the grid and resampling.
Interpret: predict
- Predictions: Using the model to make predictions on new data (test set)
Interpret: Evaluate
- Generalization: How well the model performs on new data
| Overfitting | Underfitting |
|---|---|
| When the model performs well on the training set but poorly on new data | When the model performs poorly on both the training set and new data |
Interpret: Evaluate
- Feature importance: Which variables are most important for the model’s predictions
For linear models we get coefficients, for tree-based models we get variable importance.
Interpret: Evaluate
We need to standardize the coefficients to compare them.
Wrap-up
Final thoughts
- Predictive modeling is a powerful tool for examining relationships in data which can perform tasks (as AI) or provide insights into features that are important for the outcome.
- The
tidymodelspackage provides a consistent and flexible framework for building and evaluating models
References
![]()
Predict | Quantitative Text Analysis | Wake Forest University