Transformation
Prepare and enrich datasets
Mar 20, 2024
Overview
Preparation
- Normalization
- Tokenization
Enrichment
- Recoding
- Generation
- Integration
![]()
Process

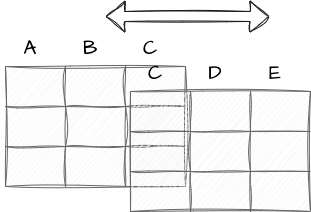
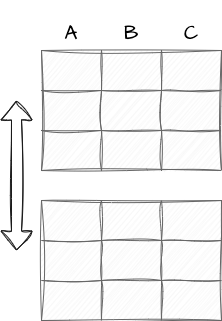
Integration
Juxapose datasets: to create a new dataset.
- Join: to add columns or rows based on a common key.
- Concatenate: to add rows to a common set of columns.
References
![]()
Mullen, Lincoln A., Kenneth Benoit, Os Keyes, Dmitry Selivanov, and Jeffrey Arnold. 2018. “Fast, Consistent Tokenization of Natural Language Text.” Journal of Open Source Software 3: 655. https://doi.org/10.21105/joss.00655.
Silge, Julia, and David Robinson. 2016. “Tidytext: Text Mining and Analysis Using Tidy Data Principles in r.” JOSS 1 (3). https://doi.org/10.21105/joss.00037.
Wickham, Hadley. 2023. Stringr: Simple, Consistent Wrappers for Common String Operations. https://CRAN.R-project.org/package=stringr.
Wickham, Hadley, Romain François, Lionel Henry, Kirill Müller, and Davis Vaughan. 2023. Dplyr: A Grammar of Data Manipulation. https://CRAN.R-project.org/package=dplyr.
Wijffels, Jan. 2023. Udpipe: Tokenization, Parts of Speech Tagging, Lemmatization and Dependency Parsing with the ’UDPipe’ ’NLP’ Toolkit. https://CRAN.R-project.org/package=udpipe.