text_id sentence_id word_id word
1 1 1 1 The
2 1 1 2 quick
3 1 1 3 brown
4 1 1 4 fox
5 1 1 5 jumps
6 1 1 6 over
7 1 1 7 the
8 1 1 8 lazy
9 1 1 9 dog
10 1 1 10 .Data
Understanding data and information
Jan 31, 2024
Overview
Up for today:
- Understanding data
- From data to information
- Documenting the process
Looking ahead:
- Recipe and lab 02

Populations and samples
Population
An idealized set of objects or events that share a common characteristic or belong to a specific category.
Sample
A finite set of objects or events from drawn from a defined population.
Tidy data
Physical structure 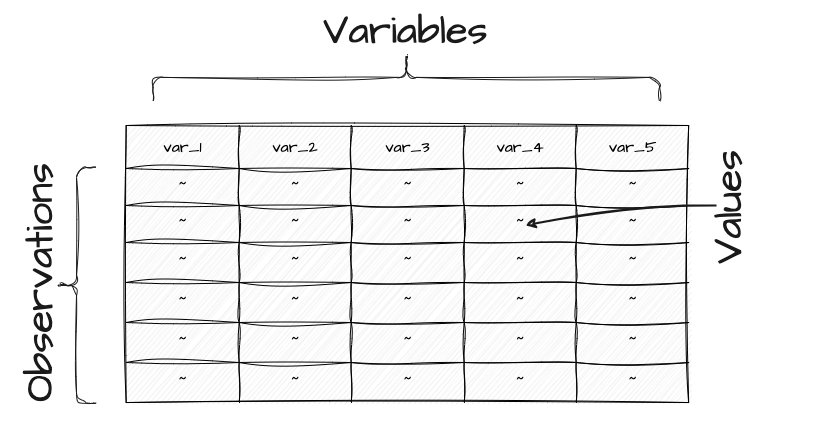
Transformation
Reshaping
Types: enrichment
Augment the dataset with additional information
- Decrease levels
- Increase levels
# A tibble: 10 × 3
word pos cat
<chr> <chr> <chr>
1 Recoding NN Noun
2 transforms VBZ Verb
3 values NNS Noun
4 to TO Preposition
5 new JJ Adjective
6 values NNS Noun
7 more RBR Adverb
8 suitable JJ Adjective
9 for IN Preposition
10 analysis NN Noun # A tibble: 11 × 6
sent_id token_id token xpos features syntactic_relation
<dbl> <chr> <chr> <chr> <chr> <chr>
1 1 1 Wow UH <NA> discourse
2 1 2 , , <NA> punct
3 1 3 this DT Number=Sing|PronType=Dem nsubj
4 1 4 is VBZ Mood=Ind|Number=Sing|Pers… cop
5 1 5 a DT Definite=Ind|PronType=Art det
6 1 6 great JJ Degree=Pos amod
7 1 7 tool NN Number=Sing root
8 1 8 for IN <NA> case
9 1 9 text NN Number=Sing compound
10 1 10 analysis NN Number=Sing nmod
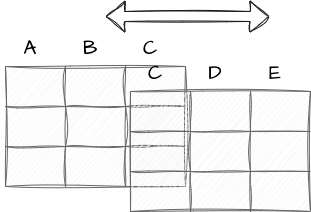
11 1 11 ! . <NA> punct Concatenate
Join
Recipe and lab
- Recipe 02: Reading, inspecting, and writing datasets
- Lab 02: Dive into datasets
![]()
Footnotes
The OANC is a large collection of written and spoken American English from 1990 onwards, with freely available data and annotations.
The Santa Barbara Corpus includes transcriptions and audio recordings of natural conversations from across the US.
The Europarl Parallel Corpus is a collection of proceedings from the European Parliament translated into 21 European languages and aligned at the sentence level to build datasets for statistical machine translation research.
The Brown Corpus is the first computer-readable general corpus of edited American English texts from 1961 containing approximately 1 million words across 500 samples.